스토리지 관리
이 실습은 다음 두 부분으로 나뉩니다.
실습의 과제에서는 다음을 생성합니다.
- Amazon EC2 인스턴스
- AWS CLI 설정
- 스냅샷 생성
- 로그 파일을 Amazon S3에 업로드
실습의 도전 과제에서는 로컬 디렉터리의 콘텐츠를 Amazon S3 버킷과 동기화하는 도전 과제가 주어집니다.
목표 이 실습을 완료하면 다음을 할 수 있게 됩니다.
- Amazon EC2 인스턴스 스냅샷 생성 및 유지 관리
- Amazon S3에 파일을 업로드하고 Amazon S3에서 파일을 다운로드
소요 시간
이 실습은 완료하는 데 약 45분이 소요됩니다.
AWS Management Console 액세스
지침의 맨 위에서 실습 시작(Start Lab)을 클릭하여 실습을 시작합니다.
실습시작(Start Lab) 패널이 열리고 실습 상태가 표시됩니다.
“실습 상태: 준비(Lab status: ready)” 메시지가 표시되면 X를 클릭하여 실습 시작(Start Lab) 패널을 닫습니다.
지침의 맨 위에서 AWS를 클릭합니다.
그러면 새 브라우저 탭에서 AWS Management Console이 열립니다. 자동으로 로그인됩니다.
팁: 새 브라우저 탭이 열리지 않는 경우 일반적으로 브라우저에서 팝업 창을 열 수 없음을 나타내는 배너 또는 아이콘이 브라우저 상단에 표시됩니다. 배너 또는 아이콘을 클릭하고 “팝업 허용(Allow pop ups”’를 선택합니다.
이 지침과 함께 표시되도록 AWS Management Console 탭을 정렬합니다. 두 브라우저 탭이 동시에 표시되어 실습 단계를 보다 쉽게 수행할 수 있게 됩니다.
실습 도중 리전을 변경하지 마십시오.
과제 1: 리소스 생성 및 구성
시나리오
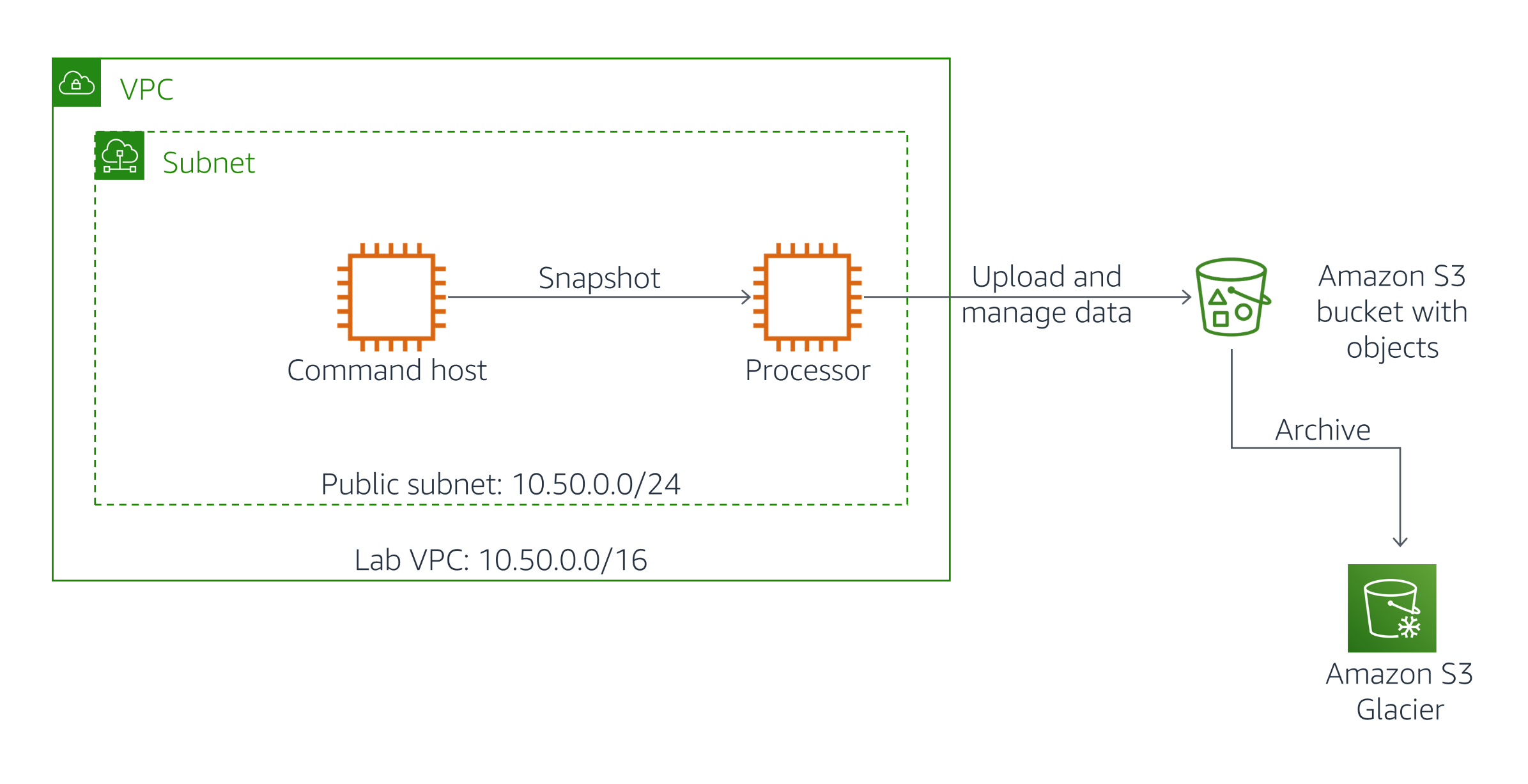
실습 환경(아래 그림)은 현재 하나의 퍼블릭 서브넷이 포함된 Lab VPC라는 Amazon VPC 인스턴스로 구성됩니다. 이 실습의 일환으로 Command Host와 Processor라는 Amazon EC2 인스턴스가 이미 생성되었습니다.
Command Host는 Processor를 포함한 AWS 리소스를 관리하는 데 사용됩니다.
이 과제에서는 Command Host에 설치된 AWS CLI를 사용하여 Processor라는 레이블이 지정된 인스턴스의 Amazon EBS 볼륨 스냅샷을 생성합니다. 그런 다음 Amazon S3에서 데이터를 가져오고 Amazon S3에 데이터를 업로드하기 위한 프로세스를 인스턴스에서 설정합니다.
Amazon S3 버킷 생성
이 하위 과제에서는 Amazon S3 버킷을 생성합니다.
AWS Management Console의 서비스(Services) 메뉴에서 S3를 클릭합니다.
버킷 생성(Create Bucket)을 클릭합니다.
버킷 생성(Create bucket) 대화 상자에서 다음을 구성합니다.
- 버킷 이름(Bucket name): Amazon S3 전체에서 겹치지 않는 버킷 이름을 입력합니다. 이후 절차에서는 이 값을 s3-bucket-name이라고 부릅니다. 나중에 사용하기 위해 s3-bucket-name을 적어둡니다.
- 리전(Region): 기본값을 그대로 둡니다.
생성(Create)을 클릭합니다.
인스턴스 프로파일을 Processor에 연결
이 섹션에서는 미리 생성된 IAM 역할을 Processor Host에 인스턴스 프로파일로 연결하여 Amazon S3 버킷과 상호 작용할 수 있는 권한을 제공합니다.
- 서비스(Services) 메뉴에서 EC2를 클릭합니다.
- 탐색 창에서 인스턴스(Instances)를 클릭합니다.
- Processor를 선택합니다.
- 작업(Actions), 보안(Security), IAM 역할 수정(Modify IAM role)을 차례로 클릭합니다.
- IAM 역할(IAM role) 아래의
S3BucketAccess역할을 선택합니다. - 적용(Apply)을 클릭한 다음 닫기(Close)를 클릭합니다.
과제 2: 인스턴스의 스냅샷 생성
이 섹션에서는 AWS Command Line Interface(CLI)를 사용하여 인스턴스의 스냅샷 처리를 관리하는 방법을 배웁니다.
어느 리전이든 AWS 계정이 보유할 수 있는 스냅샷은 10,000개로 제한됩니다. 또한 저장하는 스냅샷 데이터 1기가바이트당 요금이 매달 청구됩니다. 이 요금은 AWS가 첫 번째 스냅샷 이후 인스턴스의 증분형 스냅샷을 생성하고 스냅샷 데이터를 압축함으로써 최소화됩니다. 하지만 유지 관리와 비용을 최적화하려면 각 인스턴스의 저장된 스냅샷 수를 모니터링하여 더 이상 필요하지 않은 오래된 스냅샷을 정기적으로 삭제하는 것이 좋습니다.
Command Host에 연결
다음의 지침은 Windows를 사용 중인지 Mac/Linux를 사용 중인지에 따라 약간 달라집니다.
Windows 사용자: SSH를 사용하여 연결
이 지침은 Windows 사용자에게만 적용됩니다.
macOS 또는 Linux를 사용하는 경우 다음 섹션으로 건너뛰십시오.
AWS Management Console의 서비스(Services) 메뉴에서 EC2를 클릭합니다.
왼쪽 탐색 창에서 인스턴스(Instances)를 클릭합니다.
Command Host를 선택합니다.
아래쪽 창의 설명(Description)에서 IPv4 퍼블릭 IP(IPv4 Public IP)를 복사합니다.
작업을 완료하기 전에 이 단계에 포함된 3개의 주요 항목을 읽어보십시오. 세부 정보(Details) 패널을 연 후에는 이러한 지침을 볼 수 없습니다.
- 현재 읽고 있는 지침 위에 있는 세부 정보(Details) 드롭다운 메뉴를 클릭한 다음 보기(Show)를 클릭합니다. 보안 인증(Credentials) 창이 열립니다.
- PPK 다운로드(Download PPK) 버튼을 클릭하고 labsuser.ppk 파일을 저장합니다. 브라우저에서 이 파일은 일반적으로 다운로드(Downloads) 디렉터리에 저장됩니다.
- X를 클릭하여 세부 정보(Details) 패널을 닫습니다.
필요한 소프트웨어를 다운로드합니다.
- PuTTY를 사용하여 SSH를 통해 Amazon EC2 인스턴스에 연결합니다. 컴퓨터에 PuTTY가 설치되어 있지 않은 경우 여기에서 다운로드하십시오.
putty.exe를 엽니다.
시간 초과가 발생하지 않도록 다음과 같이 PuTTY를 구성합니다.
- 연결(Connection)을 클릭합니다.
- 킵얼라이브 간 시간차(초)(Seconds between keepalives)를
30으로 설정합니다.
이렇게 하면 PuTTY 세션을 더 오래 열어둘 수 있습니다.
다음과 같이 PuTTY 세션을 구성합니다.
- 세션(Session)을 클릭합니다.
- 호스트 이름(또는 IP 주소)[Host Name (or IP address)]: 실습 앞부분에서 클립보드에 복사한 퍼블릭 IPv4(Public IPv4) 값을 붙여넣습니다.
- PuTTy로 돌아간 후 연결(Connection) 목록에서 SSH를 확장합니다.
- Auth를 클릭합니다(확장하지 말 것).
- 탐색(Browse)을 클릭합니다.
- 다운로드한 lab#.ppk 파일을 찾아 선택합니다.
- 열기(Open)를 클릭하여 선택합니다.
- 열기(Open)를 클릭합니다.
호스트를 신뢰하고 호스트에 연결하려면 예(Yes)를 클릭합니다.
로그인(login as) 메시지가 나타나면
ec2-user를 입력합니다.그러면 EC2 인스턴스에 연결됩니다.
Mac 및 Linux 사용자
이 지침은 Mac/Linux 사용자에게만 적용됩니다. Windows 사용자인 경우 다음 과제로 건너뜁니다.
AWS Management Console의 서비스(Services) 메뉴에서 EC2를 클릭합니다.
왼쪽 탐색 창에서 인스턴스(Instances)를 클릭합니다.
Command Host를 선택합니다.
아래쪽 창의 설명(Description)에서 IPv4 퍼블릭 IP(IPv4 Public IP)를 복사합니다.
작업을 완료하기 전에 이 단계에 포함된 3개의 주요 항목을 읽어보십시오. 세부 정보(Details) 패널을 연 후에는 이러한 지침을 볼 수 없습니다.
- 현재 읽고 있는 지침 위에 있는 세부 정보(Details) 드롭다운 메뉴를 클릭한 다음 보기(Show)를 클릭합니다. 보안 인증(Credentials) 창이 열립니다.
- PEM 다운로드(Download PEM) 버튼을 클릭하고 labsuser.pem 파일을 저장합니다.
- X를 클릭하여 세부 정보(Details) 패널을 닫습니다.
터미널 창을 열고 디렉터리를 labsuser.pem 파일이 다운로드된 디렉터리로 변경(
cd)합니다.예를 들어 다운로드(Downloads) 디렉터리에 저장된 경우 다음 명령을 실행합니다.
xxxxxxxxxxcd ~/Downloads다음 명령을 실행하여 키에 대한 권한을 읽기 전용으로 변경합니다.
xxxxxxxxxxchmod 400 labsuser.pem터미널 창으로 돌아가 다음 명령을 실행합니다. 이때 <public-ip>를 실습 앞부분에서 클립보드에 복사한 퍼블릭 IPv4(Public IPv4) 값으로 바꿉니다.
xxxxxxxxxxssh -i labsuser.pem ec2-user@<public-ip>이 원격 SSH 서버에 대한 첫 번째 연결을 허용할 것인지 묻는 메시지가 나타나면
yes를 입력합니다.인증에 키 페어를 사용 중이므로 암호를 묻는 메시지는 나타나지 않습니다.
초기 스냅샷 생성
이 절차에서는 Processor 인스턴스의 초기 스냅샷을 생성합니다.
스냅샷을 만들려면 aws ec2 create-snapshot 명령을 사용합니다. 이 명령은 볼륨 ID를 사용하므로 먼저 Processor 인스턴스에 연결된 Amazon EBS 볼륨의 볼륨 ID를 찾아야 합니다. 그러려면 aws ec2 describe-instances 명령을 사용합니다.
aws ec2 create-snapshot 명령은 명령이 실행되었을 때의 디스크 스냅샷을 만듭니다. 디스크에 대한 이후의 쓰기는 스냅샷에 포함되지 않습니다. 다만 애플리케이션 및 OS 쓰기 캐싱 때문에 실행 인스턴스의 스냅샷은 일관되지 않고 데이터가 누락되거나 손상될 수 있습니다. 따라서 Processor 인스턴스의 스냅샷을 만들기 전에 인스턴스를 중지(Stop)해야 합니다. 이렇게 하면 일관된 스냅샷을 얻을 수 있습니다.
보조(비루트) Amazon EBS 볼륨의 스냅샷을 만드는 경우, 일관된 사본을 얻기 위해 스냅샷을 만들기 전에 볼륨의 탑재를 해제할 수도 있습니다. 데이터베이스 시스템(예: MySQL)을 백업하기 위해 파일 시스템을 동결해 쓰기 작업을 일시 중지하거나 복제를 사용하고 읽기 전용 복제본을 주기적으로 백업할 수 있습니다.
Processor 인스턴스의 전체 설명을 얻으려면 다음 명령을 복사하여 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws ec2 describe-instances --filter 'Name=tag:Name,Values=Processor'이 명령은 결과 설명을 이전 섹션에서 만든 새 인스턴스로 제한하기 위해 --filter 태그를 사용합니다. 이 명령은 인스턴스의 완전한 JSON 기반 설명과 모든 속성을 사용해 응답합니다. 이제 관심이 있는 데이터 하위 집합(Amazon EBS 볼륨 정보)만을 반환하도록 이 명령을 수정합니다.
이전 명령의 결과를 더욱 좁히려면 다음 명령을 복사하여 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws ec2 describe-instances --filter 'Name=tag:Name,Values=Processor' --query 'Reservations[0].Instances[0].BlockDeviceMappings[0].Ebs.{VolumeId:VolumeId}'이 수정된 명령은 --query 속성을 사용하여 Processor 인스턴스에 연결된 유일한 볼륨(루트 볼륨)의 볼륨 ID만 반환하는 JMESPath 쿼리를 지정합니다. 다음과 비슷한 응답이 수신되어야 합니다.
{
"VolumeId": "vol-1234abcd"
}
이후 명령에서는 이 값을 volume-id라고 부릅니다.
스냅샷을 생성하기 전에 Processor 인스턴스를 중지(Stop)합니다. 그러려면 인스턴스 ID가 필요합니다. 인스턴스 ID를 얻으려면 다음 명령을 복사하여 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws ec2 describe-instances --filters 'Name=tag:Name,Values=Processor' --query 'Reservations[0].Instances[0].InstanceId'이후 명령에서는 이 값을 instance-id라고 부릅니다.
Processor 인스턴스를 종료하려면 다음 명령을 복사하고 INSTANCE-ID를 사용자의 인스턴스 ID로 바꾼 다음 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws ec2 stop-instances --instance-ids INSTANCE-ID이 절차의 다음 단계로 가기 전에 다음 명령을 실행하여 Processor 인스턴스가 중지되었는지 확인합니다(INSTANCE-ID를 사용자의 인스턴스 ID로 바꿈). Processor 인스턴스가 중지된 경우, 명령이 프롬프트로 돌아갑니다.
xxxxxxxxxxaws ec2 wait instance-stopped --instance-id INSTANCE-IDProcessor 인스턴스 루트 볼륨의 첫 번째 스냅샷을 만들려면 다음 명령을 복사하고 VOLUME-ID를 사용자의 volume-id로 변경한 다음 SSH 창에서 실행합니다.
xxxxxxxxxxaws ec2 create-snapshot --volume-id VOLUME-ID이 명령은 새 스냅샷을 고유하게 식별하는 SnapshotId 값이 포함된 정보 집합을 반환합니다. 이후 명령에서는 이 값을 snapshot-id라고 부릅니다.
스냅샷의 상태를 확인하려면 다음 명령을 복사하고 SNAPSHOT-ID를 사용자의 snapshot-id로 바꾼 다음 SSH 창에서 실행합니다.
xxxxxxxxxxaws ec2 wait snapshot-completed --snapshot-id SNAPSHOT-ID명령이 완료되면 아래 절차를 계속합니다.
Processor 인스턴스를 다시 시작하려면 다음 명령을 복사하고 INSTANCE-ID를 사용자의 인스턴스 ID로 바꾼 다음 SSH 창에서 실행합니다.
xxxxxxxxxxaws ec2 start-instances --instance-ids INSTANCE-ID재시작 작업의 상태를 확인하려면 다음 명령을 복사하고 INSTANCE-ID를 사용자의 인스턴스 ID로 바꾼 다음 SSH 창에서 실행합니다.
xxxxxxxxxxaws ec2 wait instance-running --instance-id INSTANCE-ID
후속 스냅샷의 예약 생성
Linux 일정 시스템(cron)을 사용하여 반복적인 스냅샷 프로세스를 쉽게 설정해 데이터의 새 스냅샷을 자동으로 생성할 수 있습니다.
실습의 목적상 작업 결과를 확인할 수 있도록 1분 단위로 스냅샷 생성을 예약합니다. 다음 절차에서는 자동화를 사용하여 볼륨에 대해 유지 관리되는 스냅샷의 수를 관리합니다.
참고 실습의 이 섹션에서는 다음 절차를 위한 다수의 스냅샷을 만들기 위해 인스턴스를 중지하지 않습니다. 일관성을 보장해야 하는 경우, 과제 2에 설명된 것처럼 먼저 인스턴스를 중지하거나 디스크를 일시 중지하는 보다 완전한 자동화 스크립트를 개발할 수 있습니다.
매분 실행되는 작업을 예약하는 cron 항목을 만들려면 다음 명령을 복사하고 VOLUME-ID를 사용자의 volume-id로 바꾼 다음 인스턴스 안에서 실행합니다.
xxxxxxxxxxecho "* * * * * aws ec2 create-snapshot --volume-id VOLUME-ID 2>&1 >> /tmp/cronlog" > cronjob이 cron 작업을 예약하려면 다음 명령을 복사하여 인스턴스 안에서 실행합니다.
xxxxxxxxxxcrontab cronjob참고: 이 작업은 1~2분 정도 걸립니다.
후속 스냅샷이 생성되고 있는지 확인하려면 다음 명령을 복사하고 <volume-id>를 사용자의 volume-id로 바꾼 다음 인스턴스 내에서 실행합니다.
xxxxxxxxxxaws ec2 describe-snapshots --filters "Name=volume-id,Values=<volume-id>"원칙적으로 몇 분 후 하나 이상의 스냅샷이 보여야 합니다. 예상대로 작동하지 않으면 강사에게 도움을 요청하십시오.
다음 과제를 시작하기 전에 스냅샷이 몇 개 더 생성되도록 몇 분간 기다립니다.
마지막 2개의 EBS 볼륨 스냅샷만 유지
이 절차에서는 계정에 연결된 Amazon EBS 볼륨의 마지막 스냅샷 2개만 유지하는 Python 스크립트를 실행합니다.
이 섹션을 시작할 때 설명한 것처럼 스냅샷을 적극적으로 관리하면 비용이 절감되고 장기적으로 관리가 단순화됩니다. 몇 줄의 코드로 여러 AWS Software Development Kits(SDKs) 중 하나를 활용하여 불필요한 스냅샷을 삭제하는 프로그램을 만들 수 있습니다.
다음 명령을 사용하여 이전에 만든 cron 작업을 중지합니다.
xxxxxxxxxxcrontab -rCommandHost 인스턴스의 홈 디렉터리에 snapshotter_v2.py라는 이름의 파일이 있습니다. 다음 명령으로 이 파일을 검사합니다.
xxxxxxxxxxmore snapshotter_v2.py이 명령은 AWS용 Python SDK인 Boto(버전 3)를 사용하여 Python 프로그래밍 언어로 작성된 간단한 스크립트입니다. AWS CLI도 Boto로 작성되었는데, 대부분의 Amazon EC2 Linux 인스턴스에는 Boto가 사전 설치되어 있어 Python으로 작동하는 AWS 스크립트를 매우 편리하게 작성할 수 있습니다.
이 스크립트는 현재 사용자 계정에 연결된 모든 Amazon EBS 볼륨을 찾아 스냅샷을 만듭니다. 그런 다음 볼륨에 연결된 스냅샷의 수를 검사하고, 날짜 기준으로 스냅샷을 정렬한 후 가장 최근의 스냅샷 2개를 제외하고 모두 제거합니다.
snapshotter_v2.py를 실행하기 전에 다음 명령을 복사하여 인스턴스 내에서 실행합니다(VOLUME-ID를 사용자의 volume-id로 바꿈).
xxxxxxxxxxaws ec2 describe-snapshots --filters "Name=volume-id, Values=VOLUME-ID" --query 'Snapshots[*].SnapshotId'볼륨에 대해 여러 개의 스냅샷 ID가 반환되어야 합니다. 이들은 cron 작업을 종료하기 전에 cron 작업에 의해 생성된 스냅샷입니다.
다음의 snapshotter_v2.py 스크립트를 실행합니다.
xxxxxxxxxxpython3 snapshotter_v2.py스크립트가 몇 초간 실행된 다음 삭제한 모든 스냅샷 목록을 반환해야 합니다.
[ec2-user@ip-\*]$ python3 snapshotter_v2.py
Deleting snapshot snap-e8128a20
Deleting snapshot snap-d0d34818
Deleting snapshot snap-ded14a16
Deleting snapshot snap-e8d74c20
Deleting snapshot snap-25d54eed
Deleting snapshot snap-4acb5082
현재 볼륨의 새로운 스냅샷 수를 검사하려면 위 절차의 명령을 다시 실행합니다.
xxxxxxxxxxaws ec2 describe-snapshots --filters "Name=volume-id, Values=<volume-id>" --query 'Snapshots[*].SnapshotId'반환되는 스냅샷 ID 2개만 보여야 합니다.
Command Host의 SSH 연결을 끊습니다.
과제 3: 도전 과제: Amazon S3와 파일 동기화
이 섹션에서는 Processor 인스턴스에 접속하여 디렉터리의 콘텐츠를 Amazon S3 버킷과 동기화하는 도전 과제가 주어집니다.
참고 이미 AWS에 익숙하다면 다음 섹션에 있는 자세한 솔루션을 읽기 전에 이 섹션에 나온 정보를 사용하여 직접 이 도전 과제를 해결해보는 것이 좋습니다. 도전 과제를 완료하면 자세한 솔루션을 검토하여 작업을 확인하십시오.
도전 과제 설명
Processor 인스턴스에서 다음 명령을 실행하여 샘플 파일 세트를 다운로드합니다.
xxxxxxxxxxwget https://aws-tc-largeobjects.s3.us-west-2.amazonaws.com/CUR-TF-100-RESTRT-1/183-lab-JAWS-managing-storage/s3/files.zip파일 압축을 푼 다음 AWS CLI를 최대한 활용하여 다음을 달성하는 방법을 알아내십시오.
- Amazon S3 버킷 버전 관리 활성화
- 하나의 AWS CLI 명령을 사용하여 압축을 푼 폴더의 콘텐츠와 Amazon S3 버킷 동기화
- 인스턴스에서 로컬로 파일이 삭제되면 해당 파일을 Amazon S3에서 삭제하도록 명령 수정
- 버전 관리를 사용하여 Amazon S3에서 삭제된 파일 복구
힌트: aws s3api 명령을 사용하여 Amazon S3 버킷에서 버전 관리를 사용 설정할 수 있습니다.
솔루션 요약
솔루션은 다음 단계로 구성됩니다.
- 버킷의 버전 관리를 사용 설정하려면
aws s3api put-bucket-versioning명령을 사용합니다. - 로컬 파일과 Amazon S3를 동기화하려면 로컬 폴더에서
aws s3 sync명령을 사용합니다. - 로컬 파일을 삭제합니다.
- Amazon S3에는 존재하지만 로컬 드라이브에는 존재하지 않는 파일을 Amazon S3가 삭제하도록 강제하려면
aws s3 sync에--delete를 사용합니다. - Amazon S3에는 이전 버전의 파일을 직접 복구하는 명령이 없으므로 Amazon S3에서 삭제된 파일의 이전 버전을 다운로드하려면
aws s3api list-object-versions및aws s3api get-object명령을 사용합니다. 그러면aws s3 sync에 대한 또 다른 호출을 사용하여 파일을 Amazon S3로 복구할 수 있습니다.
샘플 파일 다운로드 및 압축 해제
샘플 파일 패키지에는 file1.txt, file2.txt, file3.txt라는 3개의 텍스트 파일이 있는 폴더가 포함되어 있습니다. 이것이 Amazon S3 버킷과 동기화할 파일입니다.
Processor 인스턴스에 로그인합니다.
Processor 인스턴스에 샘플 파일을 다운로드하려면 다음 명령을 복사하여 인스턴스 안에서 실행합니다.
xxxxxxxxxxwget https://aws-tc-largeobjects.s3.us-west-2.amazonaws.com/CUR-TF-100-RESTRT-1/183-lab-JAWS-managing-storage/s3/files.zip디렉터리 압축을 해제하려면 다음 명령을 사용합니다.
xxxxxxxxxxunzip files.zip
파일 동기화
콘텐츠와 Amazon S3 버킷을 동기화하기 전에 버킷에서 버전 관리를 사용 설정해야 합니다. 버전 관리를 활성화하려면 다음 명령을 복사하여(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws s3api put-bucket-versioning --bucket S3-BUCKET-NAME --versioning-configuration Status=Enabled파일 폴더의 내용을 Amazon S3 버킷과 동기화하려면 다음 명령을 복사하여(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws s3 sync files s3://S3-BUCKET-NAME/files/이 명령은 파일 3개 각각을 Amazon S3 버킷에 복사했음을 확인합니다.
파일 상태를 확인하려면 다음 명령을 사용합니다(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈).
xxxxxxxxxxaws s3 ls s3://S3-BUCKET-NAME/files/로컬 드라이브에서 파일 중 하나를 삭제하려면 다음 명령을 사용합니다.
xxxxxxxxxxrm files/file1.txt서버에서 같은 파일을 삭제하려면
aws s3 sync명령에--delete옵션을 사용합니다. 다음 명령을 복사하여(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.xxxxxxxxxxaws s3 sync files s3://S3-BUCKET-NAME/files/ --delete참고 사용 중인 AWS CLI 버전에 따라 다음과 같은 오류가 표시될 수 있습니다.
delete failed: s3://custombucketname/files/file2.txt 'str' object has no attribute 'text'
이는 한 AWS CLI 버전에서 발생하는 구문 분석 응답 오류일 뿐이며, 다음 단계에서 오류에도 불구하고 파일이 삭제되었음을 확인할 수 있습니다.
서버에서 원격으로 파일이 삭제되었는지 확인합니다.
xxxxxxxxxxaws s3 ls s3://S3-BUCKET-NAME/files/이제 file1.txt의 이전 버전 복구를 시도합니다. 파일의 이전 버전 목록을 보려면
aws s3api list-object-versions명령을 사용합니다.xxxxxxxxxxaws s3api list-object-versions --bucket S3-BUCKET-NAME --prefix files/file1.txt출력 결과에는
DeleteMarkers및Versions블록이 포함되어 있습니다.DeleteMarkers는 삭제 마커가 있는 곳을 나타냅니다. 즉,aws s3 rm작업(또는--delete옵션이 포함된aws s3 sync작업)을 실행하는 경우 파일을 되돌릴 다음 버전을 나타냅니다.Versions 블록에는 사용 가능한 모든 버전의 목록이 포함됩니다. 하나의 Versions 항목만 있어야 합니다.
VersionId필드를 찾아 그 값을 복사합니다. 다음 단계에서는 이 값을 version-id라고 부릅니다.Amazon S3 객체의 이전 버전을 자체 버킷으로 직접 복구하는 명령이 없기 때문에 이전 버전을 다시 다운로드한 다음 Amazon S3와 다시 동기화해야 합니다. 이전 버전의 file1.txt를 다운로드하려면 다음 명령을 복사하여(VERSION-ID를 사용자의 version-id로, S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws s3api get-object --bucket S3-BUCKET-NAME --key files/file1.txt --version-id VERSION-ID files/file1.txt파일이 로컬에서 복원되었는지 확인하려면 다음 명령을 사용합니다.
xxxxxxxxxxls files파일 또는 폴더의 내용을 Amazon S3와 다시 동기화하려면 다음 명령을 복사하여(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws s3 sync files s3://S3-BUCKET-NAME/files/마지막으로 새 버전의 file1.txt가 Amazon S3로 푸시되었는지 확인하려면 다음 명령을 복사하여(S3-BUCKET-NAME을 사용자의 버킷 이름으로 바꿈) 인스턴스 안에서 실행합니다.
xxxxxxxxxxaws s3 ls s3://S3-BUCKET-NAME/files/
실습 완료
축하합니다. 실습을 마쳤습니다.
이 페이지의 상단에서 실습 종료(End Lab)를 클릭하고 예(Yes)를 클릭하여 실습 종료를 확인합니다.
“삭제가 시작되었습니다.(“DELETE has been initiated...) 이제 이 메시지 상자를 닫아도 됩니다.’(You may close this message box now.’)라는 내용의 패널이 표시됩니다.
오른쪽 상단 모서리에 있는 X를 클릭하여 패널을 닫습니다.
추가 리소스
AWS Training and Certification에 대한 자세한 내용은 https://aws.amazon.com/training/을 참조하십시오.
여러분의 피드백을 환영합니다. 제안이나 수정 사항을 공유하려면 AWS Training and Certification 연락처 양식에서 세부 정보를 제공해 주십시오.
© 2022 Amazon Web Services, Inc. and its affiliates. All rights reserved. 본 내용은 Amazon Web Services, Inc.의 사전 서면 허가 없이 전체 또는 일부를 복제하거나 재배포할 수 없습니다. 상업적인 복제, 대여 또는 판매는 금지됩니다.